The 2024 Nobel Prizes in Physics and Chemistry were awarded to scientists who have successfully converged AI to their own field. AI has become an essential tool in our daily lives, and its application in various fields is now regarded as one of the most significant topics in STEM fields. Biology is one of them, and the key to this integration is the collection of biodata that AI could analyze and learn from.
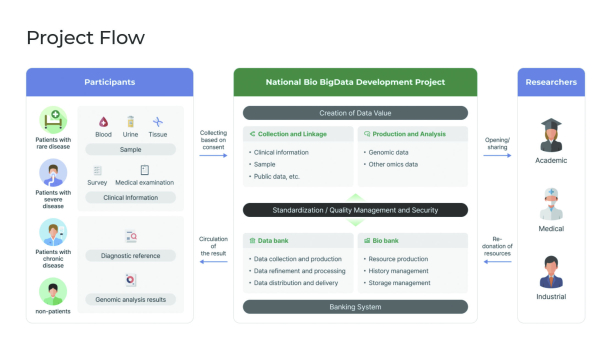
The collection of biodata is crucial in research for various diseases. Biological big data on rare diseases plays a pivotal role in identifying unknown pathways regarding diseases, which in turn can be utilized in the diagnosis and treatment of the disease. For example, genetic information of the patients suffering from a certain disease can be used to identify genetic factors for it. Such identification can be further utilized to analyze the type of diseases individuals may be susceptible to and allow early prevention of the diseases. Moreover, the availability of biological big data is also required in the development of personalized healthcare and medicine. However, experts point out that the biodata collection system in Korea is not well established.
Despite the significance of biological big data, the Korean government did not establish a public system for managing biological big data until last year. A news report from the Korea Economic Daily reveals shocking statistics on the amount of genomic data Korea has secured so far, clearly reflecting the impact of the long-lasting absence of a national system. Compared to the US, one of the leading countries of biotechnology with 840,000 genomic datasets, Korea has obtained only 3,000 datasets, accounting for merely 0.3% of what the US has secured. In December 2024, the Korean government initiated the National Project of Bio Big Data to address this issue.
Yet the strict regulation on personal health data has been pointed out to remain and to have hindered the efficiency of data collection and usage. While the project has established a foundation of data collection for the “primary use” of the data, the policies for the “secondary use” of data are still lacking. The “primary use” of data includes the utilization of biological big data for diagnosis, treatment, and research of disease. The “secondary use,” however, refers to the usage of data beyond the treatment of diseases, such as the commercial usage of the data in personalized medicine. The secondary use of biological big data, which utilizes the existing data, has a strength in efficiency because it does not require any additional costs for data collection, and is expected to maximize the benefits of the biological big data. However, addressing issues surrounding data de-identification, privacy, security, and ethics beforehand is critical. Although discussions on the de-identification of the data appear to have progressed in Korea, further deliberation on secondary use policies remains unresolved.
Another key point is that establishing mutual understanding with the public is essential. An individual’s health data is unquestionably important, personal, and sensitive, so thorough communications with individuals are crucial for their active participation in data collection. Establishing an institutional framework to protect privacy and prevent misuse of data can contribute to this, for example. One of the ways in which the health data of individuals can be misused is when insurance companies access these health data for commercial purposes. If these companies exploit personal health data such as genomic data to gain additional information about their clients who have contributed to the collection of biological data, such clients may encounter discriminatory circumstances. The US federal congress has introduced the Genetic Information Nondiscrimination Act (GINA) to resolve such concerns. The law protects genetic information providers from facing discrimination by restricting the use of genomic information in employment and health insurance. While securing an individual’s privacy and rights, the law prohibits the use of such information from resulting in increased insurance premiums or employment rejection.
Biological big data is a valuable asset to a country, especially in the fields of biological and biotechnological research. However, such information is also highly sensitive and should be protected to ensure individual privacy. Therefore, finding a balance between the efficiency of data collection and the protection of privacy is crucial. It is essential for the government to thoroughly investigate the needs of both the industry and individuals, and to come up with a solution that both could mutually agree on.
