바야흐로 기계 학습(Machine Learning)의 시대다. 현시점에서 기계 학습의 대표적인 성공 사례를 뽑으라면 대부분 OpenAI의 ChatGPT를 떠올릴 것이다. ChatGPT는 2022년 11월 30일에 처음으로 소개된 대화형 거대 생성 모델이다. 1년도 채 안 된 모델이 이렇게 인기를 끌고 있는 이유를 뽑으라 하면 일반인뿐만 아니라 연구자들도 놀랄만한 ChatGPT의 대화 생성 능력이라 하겠다. 이런 획기적인 생성 능력에 힘입어 ChatGPT는 매주 1억 명의 사용자가 꾸준히 사용하고 있다고 한다. 하지만 이렇게 영향력 있는 생성 모델이 과연 인간이 올바르다고 생각하는 가치에 부응하는 행동을 할 것인가(AI Alignment)에 대한 생각을 이제 해야 할 시기이다. OpenAI에서도 생성 모델의 부정적인 파급력을 우려해 2027년까지 AI Alignment 문제를 해결하기 위해 회사 내 계산 자원의 20% 투자를 계획하고 있다. 과연 우리는 생성 모델, 더 나아가 기계 학습 모델을 신뢰할 수 있을 것인가?
기계 학습
대답하기에 앞서 기계 학습에 대한 간략한 소개가 필요하겠다. 기계 학습을 한 줄로 요약하자면 ‘주어진 목적에 따라 데이터를 모델로 요약하는 과정’이다. 자세히 말하면 기계 학습은 데이터, 모델의 집합, 목적 함수, 및 학습 알고리즘의 네 가지 요소로 이루어져 있다. 이 요소를 기반으로 기계 학습은 다음의 순서로 학습 알고리즘을 개발하게 된다.
1. 기계가 학습해야 할 데이터를 구성해 준다.
2. 기계는 데이터를 요약하는 모델을 찾아야 한다. 모델을 정의하는 방법은 무수히 많으므로 우리는 기계가 찾아야 하는 모델의 종류를 데이터에 대한 선 지식을 이용해 제한해 준다.
3. 기계의 학습 목적을 목적 함수로 정의한다. 목적 함수는 모델이 데이터를 설명 가능한가에 대한 평가 지표이다.
4. 학습 알고리즘은 주어진 모델 집합에서 목적 함수 기준으로 데이터를 가장 잘 설명해 줄 수 있는 모델을 찾는 알고리즘이다.
기계 학습 모델을 신뢰할 수 있나?
그렇다면 이렇게 학습된 기계 학습 모델을 우리가 신뢰할 수 있을까? 아쉽게도 모델을 신뢰할 수 없는 경우를 어렵지 않게 찾을 수 있다. 여기서는 해당 사례를 △불확실성(Uncertainty) △보안(Security) △프라이버시(Privacy) △공정성(Fairness) 관점에서 간략히 소개하려고 한다.
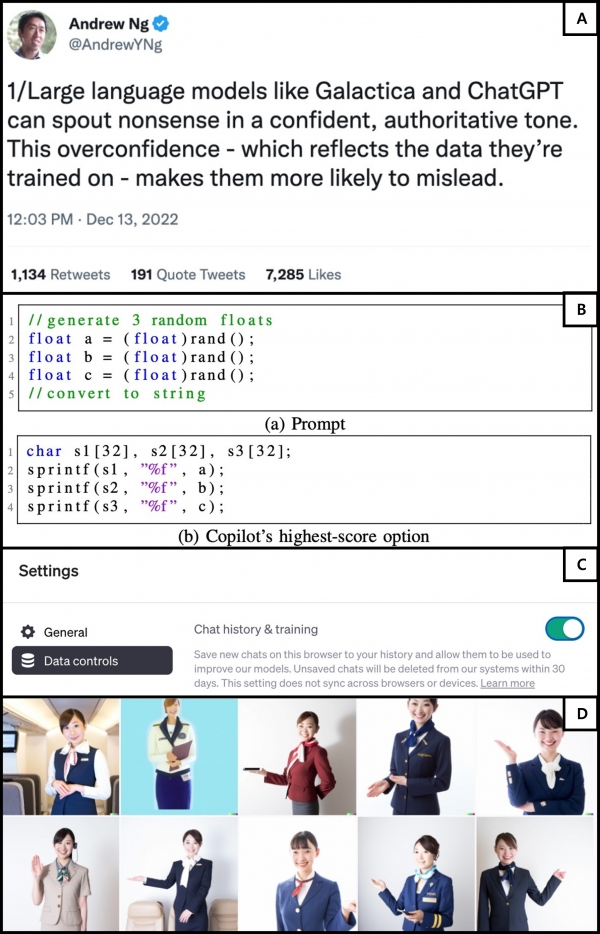
불확실성: 기계 학습 모델은 예측과 동시에 예측이 얼마나 올바른가에 대한 예측도 가능해야 한다. 이렇게 모델이 자기 자신의 예측 능력을 올바로 알고 있어야 신뢰할 수 있는 모델이라고 볼 수 있다. 하지만, 그렇지 못할 경우 모델은 확신에 찬 거짓을 자주 말하게 되고 이때 모델은 환각 효과(Hallucination Effect)를 가지고 있다고 말하고, 최근 딥러닝과 거대 생성모델에 대한 관심이 커감에 따라 기계 학습 모델 전반의 환각 효과 대한 걱정이 부각되고 있다(그림 1A).
보안: 거대 생성 모델의 발달에 따라 코드 생성 모델도 같이 발전해 왔다. 특히, Open AI Codex를 사용하는 코드 어시스턴트인 Github Copilot이 취약한 코드를 쉽게 생성한다는 문제점이 2021년도 뉴욕대의 연구 결과로 제시돼 화두가 되었다(그림 1B).
프라이버시: 모델의 학습에 사용된 데이터는 개인적인 정보가 담겨 있을 수 있다(그림 1C).
공정성: Open AI의 이미지 생성 모델의 하나인 DALL·E 2는 모델이 편견을 가질 수 있음을 경고하고 있다(그림 1D).
기계 학습 모델을 왜 신뢰하기 힘든가?
기계 학습 모델을 신뢰하기 힘든 가장 큰 이유는 신뢰할 수 있는 모델이 흔히 학습에 사용되는 목적 함수의 기준에 부합되지 않는다는 점이다. 앞선 기계 학습 소개에서 언급했듯이 기계 학습은 주어진 목적 함수를 기준으로 데이터를 가장 잘 설명해 줄 수 있는 모델을 선택하는 과정이다. 그리고 핵심이 되는 목적 함수는 정확도와 관련이 있다. 가령, 이미지 분류 모델을 학습하기 위해서는 이미지 예측 오차 확률이 목적 함수가 되고 이를 최소화하는 모델을 선택하는 것이 학습의 목적이다. 하지만 학습 목적에 신뢰할 수 있는 모델에 대한 선호도가 들어있지 않다면, 학습 목적을 최소화하는 모델은 신뢰할 수 있는 모델이 아닌 경우가 많다.

기계 학습 모델을 어떻게 신뢰할 수 있게 만드나?
기계 학습 모델을 신뢰할 수 있게 만들기 위해서는 △‘신뢰할 수 있음’의 기준에 대한 명확한 정의가 필요하고, △해당 정의에 부합하는 모델을 학습하는 기계 학습 이론(Machine Learning Theory)에 대한 올바른 이해가 필요하고, △올바르게 이해한 이론을 알고리즘으로 구현하는 작업이 수반돼야 한다. 여기서 우리는 신뢰할 수 있는 모델을 학습하기 위한 첫 단계인 신뢰할 수 있는 모델이 만족해야 하는 알려진 많은 정의 중 불확실성과 관련한 정의를 소개하려 한다.
정합 예측(Conformal Prediction)은 불확실성과 관련된 신뢰할 수 있는 모델에 대해 고찰하는 분야이다. 자세히 말하면 정합 예측에서는 주어진 모델에 대한 대답의 집합을 구하되 그 집합이 정답을 높은 확률로 포함하게 구성하는 것이 목적이다(그림 2). 이런 조건을 만족하는 집합을 정합 집합(Conformal Set)이라 하고 신뢰할 수 있는 정합 집합을 정의하는 기준으로 얼추 거의 맞는(Probably Approximately Correct, PAC) 보장을 사용할 수 있다. 여기서 정합 집합의 크기는 불확실성을 측정하는 기준으로 사용된다. 가령, 집합의 크기가 크다면 정답이 될 수 있는 대답이 많다는 말이 되므로 주어진 모델은 질문에 대한 대답에 확신이 없다는 말이고, 반대로 집합의 크기가 작다면 모델은 질문에 대한 대답에 좀 더 확신을 두고 있다는 말이다. 이렇게 구한 정합 집합을 이용해서 환각 효과를 줄일 수 있다고 본다.
남은 과제는?
거대 생성 모델을 필두로 하는 유용한 기계 학습 모델이 일상에서 흔히 사용되고 있다. 이런 거대 생성 모델을 믿고 사용하기 위해서 우리는 모델의 신뢰 가능함에 대해서 고민해야 하고, 신뢰할 수 있음을 보이는 연구에 관심을 가져야 한다고 생각한다. 이를 위해서 기계 학습 이론을 강조하는 교육 환경이 조성돼야 할 것이다.
