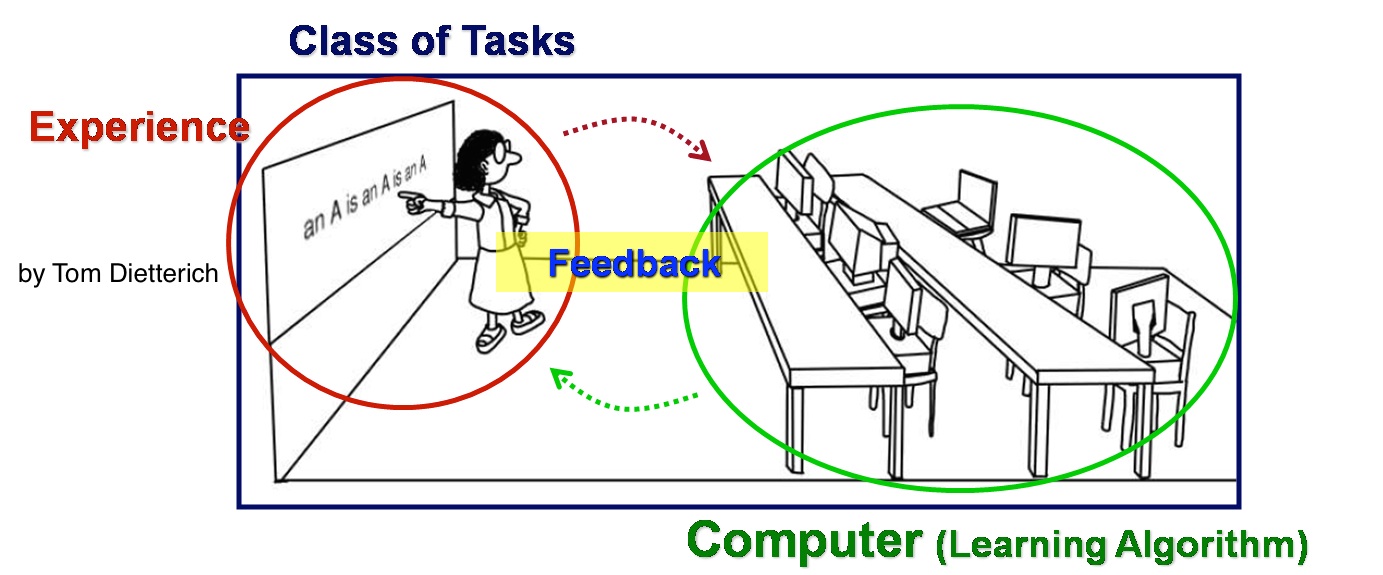
그렇다면 컴퓨터가 학습을 한다는 것이 어떤 의미이고, 왜 이것이 세상을 바꾸는 하나의 기술로까지 성장할 수 있는지에 대한 궁금증을 조금이나마 풀어주고자 한다. [그림 1]은 오레곤주립대의 토마스 디트리히(Thomas Dietterich) 교수가 만든, 기계학습을 간단히 설명하는 만화다. 교실에서 컴퓨터들이 책상에 앉아서 선생님의 수업을 듣고 있는 모습으로, 외부로부터 데이터를 얻는 것을 경험(Experience), 컴퓨터가 학습해나가는 과정을 학습 알고리즘(Learning Algorithm)으로 설명하고 있다.
추론, 또는 좀 더 엄밀히 이야기하면 확률적 추론(probabilistic inference)은 기계학습과 밀접한 관계에 있는 기술이다. 추론이란 이미 알고 있는 것으로부터 결론을 도출하는 행위 또는 과정을 얘기하는데, 기계학습에서 추론이라 함은 관측된 데이터로부터 알고자 하는 것을 예측하는 과정을 얘기한다. 예를 들면, 엄마의 표정을 보고, 목소리를 듣고, 엄마의 기분이 좋은지 나쁜지를 예측하는 일도 추론의 일종이다. 기계학습에서는 이런 예측을 사람이 하지 않고 컴퓨터가 할 수 있게 하는 알고리즘과 기술을 개발하는데, 엄마의 표정은 카메라로 영상 데이터를 받고, 목소리는 마이크로폰을 이용하여 음성데이터를 받아서 컴퓨터가 엄마의 기분 상태를 예측하게 하는 알고리즘을 개발한다.
몇 년 전 미국의 영화 DVD 대여 회사 넷플릭스(Netflix)는 자기네 회사의 영화 추천 시스템 ‘Cinematch’의 성능보다 10% 더 우수한 성능을 내는 팀에게 백만 불의 상금을 주겠다고 하며 ‘Netflix Prize’라는 이름하에 데이터를 공개하고, 여기에 많은 팀이 참여하여 약 2년간의 경쟁을 하였다. 소비자들이 그동안 평점을 매긴 데이터를 바탕으로 어떤 영화를 좋아할지 예측하는 영화 추천시스템은 기계학습의 좋은 한 가지 예이다.
100명의 소비자 각자가 1,000개의 영화 중 10개의 영화에 평점을 1에서 5까지 매겼다면 100 곱하기 1000의 사이즈를 가지는 행렬의 1%만 평점으로 채워져 있고, 나머지 99%는 빈칸이다. 주어진 1%의 데이터만 이용하여 99%의 빈칸을 완성하는 기술은 ‘matrix completion’이란 기술이고 다양한 방법들이 기계학습에서 개발되어왔다.
이는 또한 협력 필터링(collaborative filtering) 방법을 이용하여 해결하기도 한다. 협력 필터란 비슷한 성향을 가지는 소비자들을 모아서, 같은 성향의 소비자들의 평점을 바탕으로 추론하는 기술이다. 아마존에서 책을 구매한 고객들에게 좋아할 만한 책들의 리스트를 추천하여 주는데, 이 또한 협력필터가 사용된 예이다.
얼마 전 이어령 선생께서 하신 말씀인데, “요즘 젊은이들은 사색보단 검색을 한다”. 동감하는 말이고, 나 또한 책을 읽는 시간이 예전에 비하여 줄어든 것 같다는 생각이 든다. 뭔가 궁금하면 책보단 검색을 해서 빨리 요약된 내용을 파악하는데 익숙해져 가고 있다. 90년대 대학원에서 공부를 할 시절엔 논문을 읽다가 참고문헌에 있는 다른 논문을 읽으려면 도서관에 가서 하나하나 찾아서 복사를 해야했고, 이런 운이 따르지 않는다면 inter-library loan을 통하여 신청하면 약 1주일 후에 논문 복사본이 우편으로 배달되었다. 지금은 제목의 일부분만 가지고 검색을 하여도 쉽게 논문들을 얻을 수 있으니, 학문의 발전 속도는 비교가 되지 않을 정도로 빨라지고 있고, 어디서 공부를 하던 같은 정보를 쉽게 얻을 수 있다.
검색의 발전은 1998년도 창업한 구글이 많은 기여를 하였다고 볼 수 있다. 사용자가 원하는 정보를 검색하는 구글의 기술은 ‘PageRank’라는 방법인데 검색창에 단어를 입력하였을 때, 웹사이트들의 중요성을 계산하여, 관련이 높을 거로 생각되는 웹사이트들의 리스트를 보여준다. 중요한 웹사이트는 연결된 링크가 많을 거라는 단순한 가정으로부터 출발했지만, 그래프 상에서 마르코프 체인 이론으로 설명이 된다.
구글은 무인자동차, 구글 글라스 등 새로운 기술에 투자를 하고 있는데, 무인 자동차에 필요한 지능은 기계학습 방법을 이용하고 있고, 구글 글라스에서 인식, 검색, 추천 서비스 등에도 많은 기계학습 방법이 이용되고 있다. 구글이 무인 자동차를 개발하고 있는 이유는 단순히 운전자 없이 주행이 가능한 자동차가 최종 목표가 아니다. 무인 자동차 개발과 관련된 강연을 몇 년 전 듣고서 알게 된 사실은 구글은 자동차를 공유함으로써 주차장에 필요한 공간을 획기적으로 줄이고자 하는 공간 활용의 의도가 있다는 것이다. 모든 사람들이 개인 자동차를 갖고 있으면 거기에 필요한 주차 공간이 있어야 하지만, 무인 자동차가 공유가 되면 이동 수단이 필요할 시 모바일 폰, 인터넷 등으로 무인 자동차를 요청하고 원하는 장소로 무인 자동차가 데려다 준다면, 인건비 부담 없이 많은 자동차가 공유되는 세상이 오리라 생각한다.
음성 인식 기술이 모바일 폰에 적용이 되면서 보편화되고 있다. 음성 인식 역시 음성 데이터를 가지고 무슨 단어를 발음했는지 추론하는 기술이 필요하고 기계학습 방법의 하나인 은닉 마르코프 모델(hidden Markov model)이 사용되고 있다. 지난 30년간 음성 인식에 대한 연구가 많이 진행되어왔지만, 30년간의 한계를 뛰어넘은 기술은 몇 년 전 구글에서 나왔다. 딥 러닝(deep learning)은 다층 구조 네트워크(multi-layer network)을 이용하여 학습을 하는 모델로서, <MIT Technology Review>에서는 2013년 10대 기술 중의 하나로 선정했다 [그림 2]. 캐나다 토론토대 컴퓨터공학과 그레고리 힌톤(Geoffrey Hinton) 교수가 개발한 방법으로 사람의 두뇌에서 정보처리가 다층 구조를 가지고 있다는 점을 모방하려고 출발한 기술이다. 힌톤 교수의 학생들이 몇 년 전 구글에서 인턴을 하면서 딥 러닝 기술을 음성 데이터에 적용하여 특징을 추출하였더니 음성 인식 성능이 향상되어 그 후 본격적인 연구가 시작되었다. 최근 들어 몇 개의 딥 러닝 관련 벤처 회사들이 구글에 인수되었다.
대표적인 소프트웨어 기업을 꼽으라면 애플과 마이크로소트를 생각하게 된다. 각각 1976년, 1975년에 창립되어 개인용 컴퓨터 시장에서 우열을 다투었던 기업들이다. 개인용 컴퓨터와 운영체제가 주요한 상품이었지만, 애플은 이미 아이팟, 아이폰, 아이패드를 세상에 내놓으며 새로운 서비스를 개척하고 있고, 마이크로소프트 역시, 사람처럼 듣고 보고 생각하는 컴퓨터를 만들어 더 편한 세상을 만들고자 하는 목표를 가지고 있다. 좋은 소프트웨어가 이 두 회사의 강점이었지만, 이제는 소비자들의 생활을 편리하게 하는 소프트웨어와 서비스 두 가지가 같이 어우러져야 한다. 데이터를 활용하고 추론 기술을 기반으로 하는 서비스가 이 두 거대 회사가 추구하고 있는 방향이다.
무인 비행기 드론이 책을 배달하는 시대가 아마존에 의하여 곧 올 것이고, 사람들의 인맥과 온라인상에서의 교류를 분석하여 친구를 추천해주는 페이스북도 기계학습과 추론에 대한 연구를 본격화하고 있다. 기계학습은 인간의 지능을 넘어서고자 하는 기술이 아니라, 인류의 생활을 편하게 해주기 위하여 우리의 수고를 조금은 덜어주는 기술을 연구하는 것이라 할 수 있겠다.
인간과 같이 끊임없이 학습이 가능한 ‘lifelong learning’이 차세대 기계학습의 목표이고, 이러한 연구를 위하여 국내최초로 기계학습센터를 우리대학에 유치하였다. 미국과 유럽의 명문 대학들에서 우수한 학생들이 선택하여 공부하고 있는 기계학습 분야에서 우리가 경쟁하기 위해서는, 국내 최고의 학생들 아니 세계 최고의 학생들이 공부하는 우리대학에서 보다 많은 학생이 기계학습에 관심을 가지고 공부를 했으면 하는 바람으로 이 글을 끝맺는다.
저작권자 © 포항공대신문 무단전재 및 재배포 금지
