
우리는 눈을 통해 사물을 본다. 3차원 사물은 하나의 상, 즉 사진으로 맺히는 과정을 거친다. 바늘구멍 카메라를 떠올려보자. 안이 검은 상자에 빛이 들어오도록 작은 구멍을 뚫어두면, 신기하게도 박스 안에 있는 구멍의 반대 면에 예쁜 상이 맺힌다. 이것은 우리가 있는 빛의 공간에서 바늘구멍만 관통하는 특정한 빛다발만을 모아 보면서 생기는 현상이고, 3차원 물체의 공간 좌표계가 2차원 사진의 좌표계로 바뀌는 과정이다. 이 과정은 흥미롭게도 수학적으로 표현할 수 있다.
3차원에서 2차원으로 사물에서 사진이 되는 관계를 역으로 계산할 수 있다면 어떨까? 사진만으로 3차원 사물의 모양을 알 수 있지 않을까? 답은 다시점 사진을 이용한 방법에 있다. 같은 물체를 다시점, 즉 서로 다른 각도에서 보면 거리를 파악할 수 있는 것이다. 이런 기법은 우리가 보는 물체의 복원뿐만 아니라, 다중 인공위성 기반의 GPS 기술이나 천체의 거리를 파악하는 데도 쓰이고, 로봇이 어느 방향으로 얼마만큼 움직였는지도 알 수 있게 해준다. 수많은 동물의 눈이 두 개인 것도 거리를 파악하고, 시야를 넓히기 위한 연유다.
그럼 어떻게 사진으로 3차원 모양을 복원할까? 길을 가다 본 멋진 꽃을 카메라를 움직여가며 여러 장 찍었다고 생각해보자. 고전적인 방법은 사진에서 꽃이 가지고 있는 고유하고 특징적인 사진 조각을 만든 다음, 다른 사진에서 같은 조각들을 찾아내 연결해본다. 그러면, 재미있게도 꽃의 사진 조각이 실제 3차원 공간의 어디에 있었는지, 그리고 카메라의 위치와 방향을 거꾸로 알아낼 수 있다. 혹시 인체를 3차원으로 복원하는 3D 스캐너를 본 적이 있는가? 이치는 앞의 설명과 동일하다. 수많은 카메라가 사람을 감싸는 스튜디오에 들어가면, 한 번에 고해상도 다시점 사진을 촬영하고, 사진을 촘촘하게 맞춰가면서 사람의 얼굴 모양을 복원하는 것이다. 사진은 픽셀, 혹은 화소로 구성된다. 만약 사진에 있는 수백만에서 수억 개의 화소들을 총동원해 사물을 복원하면 매우 현실감 있는 물체를 만들 수 있다. 하지만 최근에는 이런 고전적 기법을 뛰어넘는 획기적인 접근법이 눈부시게 개발되고 있다. 일례로, 깊은 인공신경망(Deep neural network)을 하나의 함수처럼 사용하는 것이 골자로, 3차원 공간과 2차원 사진의 관계를 잇기 위한 ‘만능함수’로서 사용하자는 아이디어다. 예를 들어 인공신경망에 3차원 공간의 좌표를 넣어준 뒤 그 공간에 물체가 있는지, 만약 있다면 어떤 색깔인지를 맞히는 문제를 끊임없이 인공신경망에 출제하는 것이다. 인공신경망은 학습 데이터를 주면 반드시 그 최적의 대응 관계를 스스로 학습하기에, 사진을 보면서 스스로 답을 찾게끔 된다. 뚱딴지같은 이야기로 들리지만, 이런 기법을 통해 인공신경망이 실제 사진들로 학습할 수 있음이 입증됐다. 학습이 끝난 인공신경망은 주어진 공간에 대해 만물박사로 거듭난다. 3차원 공간에서 물체가 차지하는 영역과 그에 따른 색을 알고 있기에, 신기하게도 학습 때 보여주지 않았던 새로운 시점의 사진도 척척 만들어낸다.
하지만 위의 과정에서 간과된 부분이 있다. 사진을 찍었을 때 그 사진이 가진 고유한 카메라의 특징과 촬영한 각도를 정확히 알고 있어야만 한다는 것이다. 필자의 연구팀은 카메라 정보를 추가로 알아내는 새로운 기법을 최근 제안했다. 즉 사진만 주어져도 카메라의 위치와 렌즈의 정보를 스스로 알아낸 다음, 카메라 정보를 반영해 인공신경망 학습에 활용하고, 입력 사진을 딥러닝 모델로 온전히 표현할 수 있도록 학습하게 한 것이다. 쉽게 말해, 어떤 종류의 사진이 있더라도 추가적인 가정 없이 인공신경망 학습을 위해 사용할 수 있게 된 것이다. 그림 1은 이런 일련의 과정을 설명하고 있다.
최근에는 더 재미있는 방향이 제시되고 있다. 우리가 3차원 공간과 2차원 공간을 잇는 만능함수로 꼭 인공신경망을 써야 할까? 최근에는 인공신경망을 사용하지 않고, 3차원 격자 공간(Voxel grid)에 이미지 생성을 위한 최소한의 정보를 저장해두는 방식이 제안됐다. 이 기법은 보이는 각도에서 3차원 격자들이 가진 정보들을 꺼내 새 이미지를 만든다. 흥미롭게도 육면체 격자 공간을 주면, 사진 정보를 저장하는 3차원 공간 자체가 실제 물체의 3차원 모양과 흡사하게끔 자연스럽게 최적화된다. 그래야만 원래 이미지와 흡사하게 만들 테니 어찌 보면 당연하다. 쉽게 설명하면, ‘방망이 깎는 노인’처럼 끊임없이 모양을 깎고 다듬으면서 원래 보여준 사진을 만들 수 있는 격자 공간을 만들어 낸다는 의미이다.
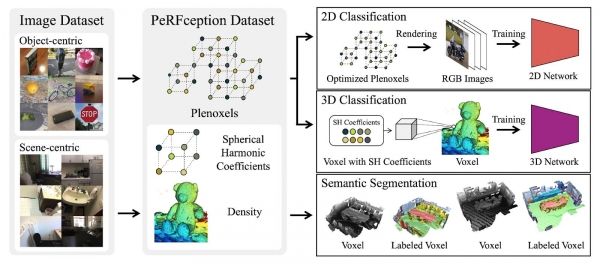
이제 모든 비밀은 풀린 것일까? 아직 아니다. 앞서 학습시킨 ‘만능함수’들은 주어진 학습용 이미지에 대해서만 동작하는 제한적인 방법이다. 이제 마음이 바뀌어 연말 선물로 받은 테디 베어를 가져와 복원하고 싶다면, 전에 학습시켜 둔 만능함수는 버리고, 새로운 만능함수를 학습시켜야 한다는 이야기이다. 그런데 만약 수많은 실제 사물에 대해 만능함수들을 잔뜩 학습시켜 두면 어떨까? 필자의 연구팀은 14,000여 개의 물체와 공간에 대해 14,000여 개의 만능함수를 학습시켜서, 만능함수의 종합세트를 세계 최초로 구축해 ‘PeRFception’이라 이름 지었다(그림 2). 앞에서 설명한 대로 만 개가 넘는 각각의 만능함수들은 고유한 물체의 모양을 갖기도 하며, 사진을 바로 만들어 주기도 한다. 필자가 포함된 연구팀은 이 만능함수들을 활용해 종류 구분(Classification), 의미론적 이해(Semantic segmentation) 등의 시각 지능 문제에 활용해보고 있다. 이는 기존의 패러다임과는 분명히 다르다. 기존에는 사진을 찍은 다음, 사진을 불러와 물체를 알아보거나 물체의 영역을 찾아냈다. 반면 지금 소개하는 기법은 ‘사진을 찍어낼 수 있는 만능함수’를 가져다 ‘이미지라는 매개체 없이’, ‘만능함수 자체를 보고’ 인식 문제에 활용한다는 점에서 큰 차이를 보인다.
여러분의 사진들은 어떤 이름으로 저장돼 있는가? ‘친구와_함께.jpeg’, ‘웃긴_클립.gif’ 등일 것이다. 앞으로 우리는 JPEG, GIF가 아닌 새로운 데이터 타입을 보게 될 가능성이 높다. 즉, 사진 한 장만을 저장하는 방식이 아니라, ‘만능함수’들을 저장하는 새로운 데이터 타입이다. 그러면 나중에 그것을 꺼내어 우리가 원하는 각도로 보고 싶은 시점의 사진을 볼 수도 있고, 3D프린터에 넘겨서 3차원 출력도 가능해질 것이다. 물론 메타버스 플랫폼에도 넣을 수 있게 될 것이다. 그런 날이 오기까지 오늘도 많은 포스테키안이 연구에 매진하고 있다.
