초기의 많은 과학자들은 우연과 열성적인 노력으로 획기적인 연구성과를 낼 수 있었다. 그러나 연구의 중심이 과학자 개인에서 기업과 국가로 넘어온 오늘날의 연구체계에서는 더 이상 이런 우연과 노력만으로 과학적 성과를 내는데 한계가 있다. 특히 80년대 후반, 대학과 국가 연구소 주도의 연구개발 체제에서, 기업주도의 연구개발 체제로 변환된 우리나라는 체계적인 연구개발 전략을 바탕으로 연구를 기획하고 수행하는 것이 일반화되고 있다. 즉 연구의 효과성과 효율성을 고려한 연구개발 체제를 개발하여, 어떻게 유망한 과학기술을 찾아내고 어떻게 이를 육성ㆍ발전시킬 것인가에 대한 연구가 연구 수행 자체만큼이나 중요해지고 있다.
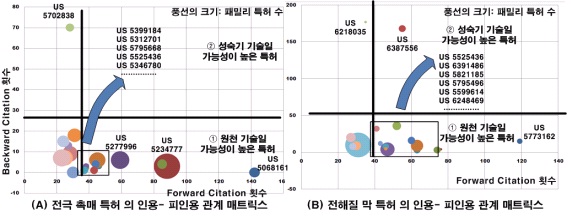
이러한 노력들은 대표적으로 특허와 논문 등과 같은 기술문서를 분석하여 정량적으로 기술정보를 분석하여 기술의 흐름을 나타내는 과학기술정보 분석 방법론(Biliometrics or Scientometrics)으로 나타나고 있다. 과학기술정보 분석 방법론에서 수행되는 기술분석 방법은 일반적으로 기술문서의 서지 정보를 분석하여 정량적으로 기술정보를 분석하는 기법과 텍스트 마이닝을 활용하여 문서의 내용을 분석하는 기법으로 나눌 수 있다.
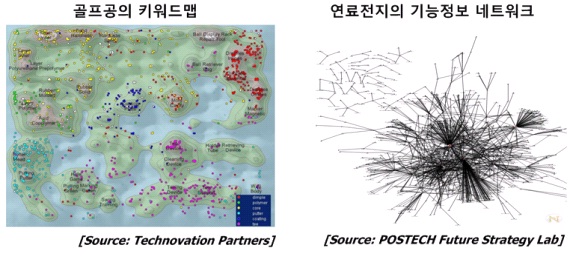
또한 기술문서의 내용을 바탕으로 텍스트 마이닝을 수행하여 기술정보를 분석하는 방법론이 있다. 텍스트 마이닝은 비정형 데이터인 문서로부터 유용한 정보를 추출하고 가공하는 기술로써, 과학기술정보 분석 방법론에서는 기술문서에 존재하는 단어와 단어구들이 한 문서에 동시에 출현하는 패턴을 파악하여 기술 간의 관계를 분석하는 기법인 동시단어 분석이 흔히 사용된다. 이러한 동시단어 분석 기법을 통하여 핵심 기술 키워드를 발견하거나, 주요 키워드 간의 관계를 분석하는데 유용한 도구로 활용되고 있다. <사진 2>는 특허 키워드 분석 도구인 유레카(Eureka)에 의해 작성된 기술 키워드 지도로써, 1981년 이후 골프공과 관련된 특허에 대한 기술지도이다. 해당 기술지도에서 키워드 간의 거리는 하나의 문서에서 동시에 출현한 정도를 나타내고, 높이는 출현빈도를 나타내고 있다. 연구자들은 아래의 기술지도를 이용해 기술 키워드간의 관계를 파악하고 새로운 연구개발에 활용할 수 있다.
텍스트 마이닝을 활용한 또 다른 분석 방법은 기능 정보를 활용한 분석이다. 여기서 기능이란 ‘어떠한 주체가 어떤 대상의 특성을 바꾸는 작용’을 의미하는 것으로, 기술의 목적이나 기술이 다른 개체에 주는 영향 등을 나타낸다. 기술문서의 기능정보를 표현하기 위해 SAO (Subject-Action-Object, 주어-동사-목적어) 모델이 일반적으로 사용된다. SAO 모델은 기술의 기능정보를 표현하는 가장 간단한 표현기법으로, 주어-동사-목적어 구조에서 주어는 주로 기술을 의미하며 동사-목적어는 기술의 기능을 표현하고 있다. SAO 모델을 NLP(Natural Language Processing) 기술 사용하여 기술문서로부터 추출한 후 분석하면 동시출현분석이 제공하지 못하는 기술 목적에 관한 분석이나 기술문서간 유사성에 관한 분석이 가능하다. 예를 들면, 기술 문서에서 SAO 정보를 추출하여 네트워크를 구축하고, 이를 네트워크 분석기법으로 분석한다면, 해당 기술 분야에서 가장 중점적으로 개발되고 있는 기술개발의 목적이나 중요한 기술지표 등을 파악할 수 있다.
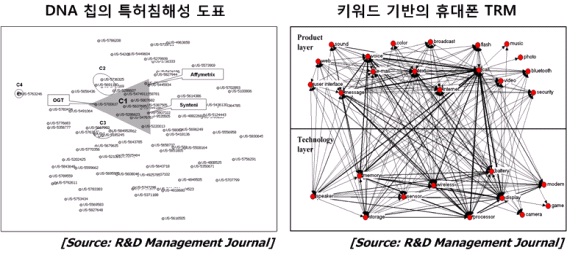
이상 언급된 서지정보분석과 텍스트 마이닝을 활용한 분석을 통합하여 기술정보를 분석한다면 좀 더 다양한 기술정보를 파악할 수 있다. 즉 기술문서의 서지정보사항 중 저자 정보나 출판년도 등을 사용하면 특정 연구자들이 주로 사용하는 기술 키워드 간의 관계를 파악할 수 있고, 시계열 데이터를 바탕으로 새롭게 출현하는 키워드나 기능정보를 파악할 수 있다. 관련연구로 DNA Chips에 관련된 특허에서 SAO 모델을 추출하여 특허간의 유사성을 비교한 후 침해 가능성을 파악한 연구가 있으며, 시계열 데이터를 바탕으로 휴대폰 분야의 주요 키워드를 활용하여 기술로드맵을 작성한 연구가 존재한다.
기술은 나날이 발전하고 있고, 기술 지식은 날로 다양해지고 있다. 새로운 기술을 개발하기 위한 기업들의 투자규모는 날이 갈수록 증가하고 있으며, 더욱더 많은 인력들이 기술개발을 위해 뛰어들고 있다. 이제는 미래에 필요한 중요기술을 먼저 파악하고 빨리 뛰어들어 최소한의 비용으로 해당 기술을 선점하는 것이 매우 중요한 시대가 되었다. 그러나 정보의 홍수로 인해 중요한 기술을 파악하기 위한 비용과 시간은 더욱더 늘어나게 되었다. 과학기술정보 분석 방법론은 이러한 시대적 요구를 반영하고 있는 새로운 학문 분야이다. 연구를 올바르게 하는 것보다(Do the research right) 올바른 연구를 하는 것이(Do the right research) 필요한 시대가 온 것이다.
여러 국내외 기업들과 함께 포스텍도 연구에 대해 새로운 도전의 시대를 맞고 있다. 전략적으로 학교의 연구개발 체계를 구축하여 시대에 요구에 부응한 연구를 수행해 나가는 체계가 필요한 시점이다. 과학기술정보 분석 방법론은 이러한 시대의 요구를 적절히 지원할 수 있는 도구로써, 대학의 연구개발 업무에 적용한다면 대학 연구개발의 효율성과 효과성을 증대할 수 있을 것으로 생각된다. 연구자가 직접 과학기술정보 분석 방법론을 사용할 수 없더라도, 국가기관인 과학기술 정책 연구원(http://www.stepi.re.kr/) 이나 한국과학기술기획평가원(http://www.kistep.re.kr/) 등에서 관련 연구자료를 배포하고 있다. 대학 연구원들의 관심을 통하여 포스텍의 연구수준만큼, 연구개발 체계도 세계적인 수준으로 올라서기를 기대해 본다.
